
가장 DeepSeek의 파급력을 보여준 내용이 바로 이 부분이다. 그동안 GPU와 서버 판매에 있어서는 과잉투자를 강요해왔다. 과소투자해서 오는 손해가 더 크다고 해왔으며 GPU 수급 문제도 있기 때문에 회사들이 일단은 GPU/서버를 사들일 수 밖에 없는 구조였다. 다만 DeepSeek에선 대중 수출 정책과 함께 적은 GPU 사용으로도 뛰어난 LLM을 만들어 성능을 보장함을 논문을 통해 보였다.
개인적으로는 이로 인해 사람들이 굳이 과잉투자를 해야할까? 서버 살 돈으로 사람을 갈아넣으면 되지 않나? 라는 의문점을 갖게 되고 Nvidia 주가가 크게 떨어지지 않았나 하는 생각이 든다.
물론 H800외에 다른 GPU들도 많이 갖고 있고(officially/non officially) 그동안의 시행착오는 포함되지 않은 금액이기 때문에 정말 저 수치만큼만 돈이 든 것은 아니다. 그동안 구매해온 GPU 자체 비용도 매우 거대하기 때문이다.
참고로 위의 표는 V3기준이고 R1은 추가 자원이 소비되었을 것으로 추정된다(R1 논문에선 언급X)
Technical
V3 Training
2048 Nvidia H800 GPU w/ 57d
H800은 H100을 성능과 대역폭(BW)를 하향 조정한 버전이다(대중 수출 규제)
FP16과 FP8은 동일한 성능이고 FP64에서만 대폭 감소한다.(FP32는 H800 문서마다 차이가 있으나 동일 성능으로 추정된다)

H800을 저성능이라 표현하는게 반은 맞고 반은 틀리다고 본다. 처리하는 칩 자체는 조금 전 언급한 것처럼 FP64 빼고 동일 성능인데 이는 LLM에선 어차피 쓰지 않는 부동소수점 단위이기 때문에 LLM에서의 성능은 H800이나 H100이나 동급으로 볼 수 있다. 하지만, bandwidth 제한 때문에 저성능이라고해도 맞는 표현이다. (PCIe는 BW가 동일하게 되어있는데 어차피 저정도 칩이면 PCIe가 아니라 DGX로 구성해서 NVLink 쓰는 환경이기 때문에 무시한다.)
결과적으로 BW 제한으로 인해 '통신 속도'가 중요하게 작용하고 이를 해결하기 위해 최적화를 시도한 것으로 보인다.
V3 Inference
Huawei Ascend 910C(H100의 60% spec)
- FP16: 800TFLOPs
- BW 32.2TB/s
PTX(Parallel Thread eXecution)
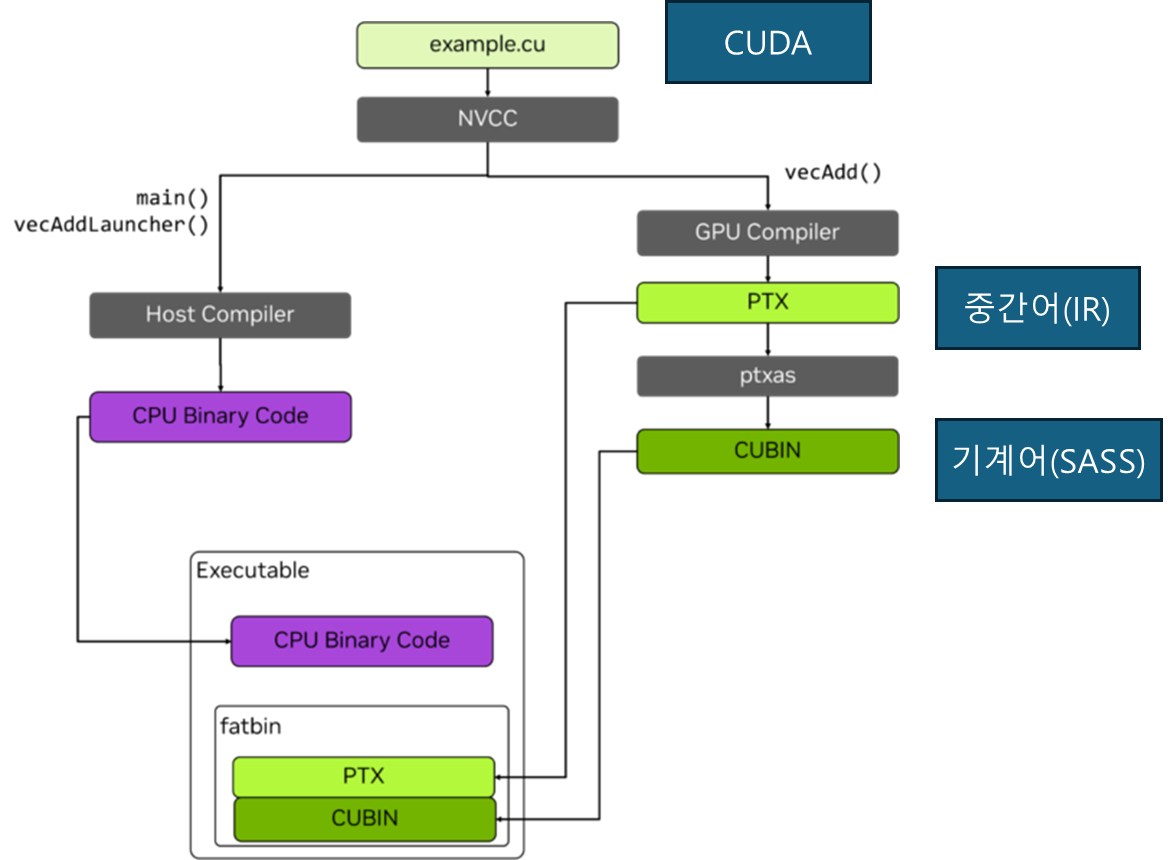
대부분 Nvidia GPU를 사용하고 이로 인해 CUDA를 사용한다. CUDA 언어는 중간어에 해당하는 PTX로 변환되고 이 PTX는 이후 기계어로 번역되어 실행된다고 생각하면 된다.
DeepSeek 개발진은 CUDA 레벨에서 코딩하는 것을 넘어 PTX 레벨에서 코드를 짰다. 이로 인해 GPU 내부의 자원을 좀 더 정밀하게 사용하여 최적화를 이끌어 냈다.
가장 큰 점은 SM(Streaming Multiprocessor)을 최적화한 부분이다. PTX를 통해 H800의 132개의 SM 중 20개를 서버간 통신에만 사용했다. 이를 통해 통신 대기로 인한 GPU 자원 낭비를 감소시켰다.(SM은 각각 고유 메모리, 캐시, 컴퓨팅 코어를 가진다.


다만 PTX는 하드웨어 종속적으로 코딩을 하기 때문에 추후 scale up을 진행하게 되어 blackwell이나 다른 GPU로 가게 될 경우 다시 코드를 짜야하는 문제점이 생길 수 있다. (어차피 사람 갈아넣으면 되긴 하는데...)
FP8 idea
V3논문에서 제시한 내용이다.

노란색 부분이 bottleneck을 일으키는 주 요소이다. dispatch는 분배, combine은 합산하는 곳이다. 중간중간 부동소수점 표현이 다르게 적용되어 있는데 Embedding module, output head, MoE gating modules, norm operators, attn operators는 기존의 BF16, FP32를 유지하여 성능 저하를 방어하려한 것으로 보인다.

오른쪽 부분을 보면 4번의 FP8 연산 이후 FP32 연산을 CUDA Core로 넘겨서 수행하는 것을 볼 수 있다. 낮은 정확도로 인해 생기는 누적 오차를 4번 곱할 때마다 FP32 Register로 보내어 보정하는 과정을 거친다. Figure 6의 노란 부분을 보면 SUM 이후 FP32로 되어있는 것을 확인할 수 있다. Figure 7이 Figure 6의 노란 부분이라고 생각하면 된다.
추가적으로 최적화를 위해 작업한 것들이 있다.
H100/H800의 FP8은 E4M3, E5M2를 지원한다. DeepSeek는 E4M3를 택했다. backward pass에선 E5M6(customized) 방식을 사용했다고 한다.
AdamW에 FP32대신 BF16을 사용했다
Input activation function 에 SwiGLU를 사용했다.
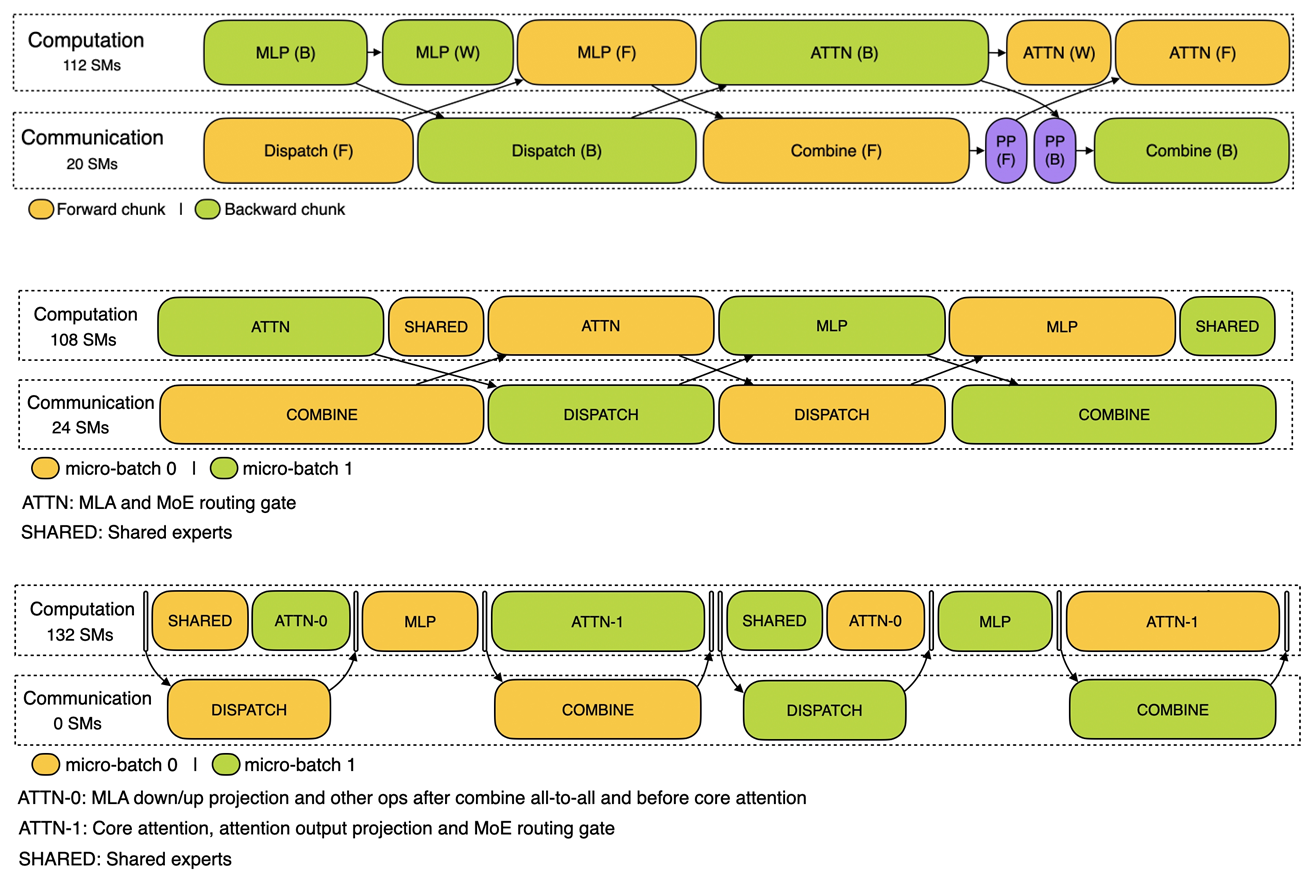
위의 그림은 논문에는 없고 DeepSeek Github에 있는 그림이다. 경우에 따라 SM을 분할하는 개수를 나누었다. Prefilling은 입력 토큰을 모델이 넣어 초기 내부 상태를 설정하는 단계이고 Decoding은 준비된 상태에서 토큰을 생성하는 단계이다.
총평
크고 작은 부분에 최적화가 매우 많이 들어갔다. 현재 이 글 작성시점에서 Llama 4가 공개되었는데 Llama 4에도 DeepSeekMoE의 아이디어가 적용되어 있던게 눈에 보였다. Nvidia의 CUDA가 독점적이고 성능이 좋기 때문에 어찌되었든 한동안 Nvidia GPU를 피할 수 없겠다만 DeepSeek는 Inference에서 Huawei 칩을 쓴 게 특이하다고 생각이 된다. SW나 HW나 AI에 있어 중국의 성장이 무서울 정도로 빠른게 사실인데 CUDA 종속성만 해결이 된다면 Training에서도 Huawei를 쓰고 사용자의 LLM 사용에 있어서 OpenAI를 더 위협할 가능성이 보인다. 당장 PTX 레벨에서 코딩한 것만 봐도 그냥 Huawei 칩에 종속적으로 코딩해서 다른 모델을 만들어 낼 수 있지 않을까 생각이 든다.
추가 참고 : https://www.youtube.com/watch?v=sg44A1nU9n4(안될공학)
추후 참고: https://arxiv.org/pdf/2504.07866(Huawei Ascend NPU)
끝.
'AI > LLM' 카테고리의 다른 글
| PANGU ULTRA: PUSHING THE LIMITS OF DENSE LLMs ON ASCEND NPUs (1) | 2025.04.22 |
|---|---|
| DeepSeek R1 정리 #6 (0) | 2025.04.21 |
| DeepSeek R1 정리 #5 (V3_Parallelism 및 마무리) (0) | 2025.04.21 |
| DeepSeek R1 정리 #4 (V3_MTP) (0) | 2025.04.21 |
| DeepSeek R1 정리 #3 (V2_MLA) (0) | 2025.04.21 |