DeepSeekMoE
가장 널리 알려진 ChatGPT의 T가 Transformer에 해당한다. 기존엔 Transformer 기반으로 모델을 구성하였으나 Transformer 내부의 FFN(Feed Forward Network)의 크기가 매우 큰게 문제였다.
이를 해결하고자 MoE(Mixture of Experts)라는 아이디어가 등장한다. 기존 FFN을 여러 개의 소형 FFN(=Experts)으로 분할하고, 내부에 Router라는 또 하나의 FFN을 둔다.
Router는 기본적으로 네트워크 상에서 패킷의 경로를 결정하는 장치이다. 이러한 의미에 맞게 소형 FFN들 중 일부 FFN을 선택해서 training/inference를 진행한다.(한 마디로 전체 FFN이 아닌 일부 FFN을 사용)

(참고로 experts는 코딩/물리/수학/철학/... 이런 분야를 나눈 전문가를 의미하는 것이 아니다.)
DeepSeekMoE는 이런 MoE 구조를 추가 변형하여 Shared Expert라는 개념을 사용한다.
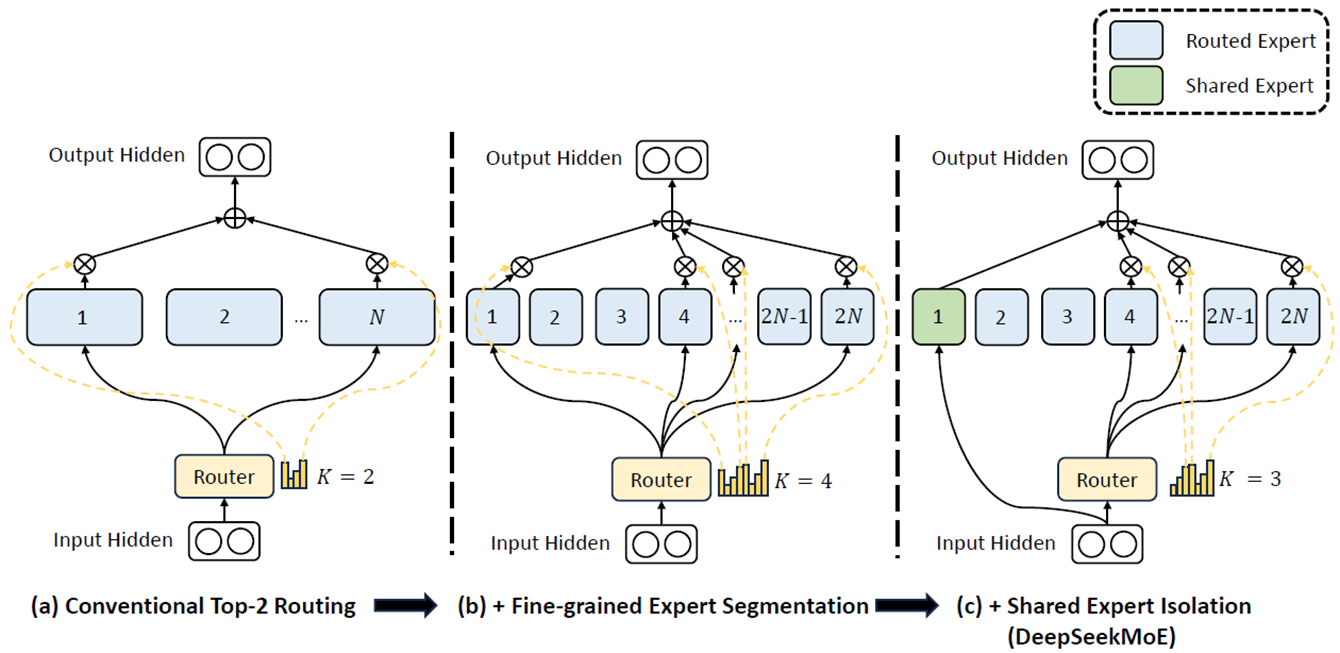
(a)기존에 N개의 Experts 중에 2개를 선정했다면, (b)Experts 크기를 절반으로 나누고 4개로 선정한다. 이는 각 전문가를 더 작고 더 집중된 기능을 하는 부분들로 세분화하는 것이다. 이후 (c) 1개를 Shared Expert로 두고, 나머지 2N-1개 중에 3개를 라우터가 선정하게 한다. Shared Expert는 매번 고정적으로 선택되는 expert로, 여러 작업에 필요할 수 있는 공통 지식을 처리한다고 생각하면 된다. 현재 그림 상에서는 1개의 Shared Expert를 사용한다고 되어있지만 추후 DeepSeek V3, R1에선 경우마다 개수가 다르다
'AI > LLM' 카테고리의 다른 글
| DeepSeek R1 정리 #5 (V3_Parallelism 및 마무리) (0) | 2025.04.21 |
|---|---|
| DeepSeek R1 정리 #4 (V3_MTP) (0) | 2025.04.21 |
| DeepSeek R1 정리 #3 (V2_MLA) (0) | 2025.04.21 |
| DeepSeek R1 정리 #1 (0) | 2025.04.21 |
| DeepSeek R1 정리 #0 (0) | 2025.04.21 |