DeepSeek R1 정리 #3 (V2_MLA)
DeepSeek-V2
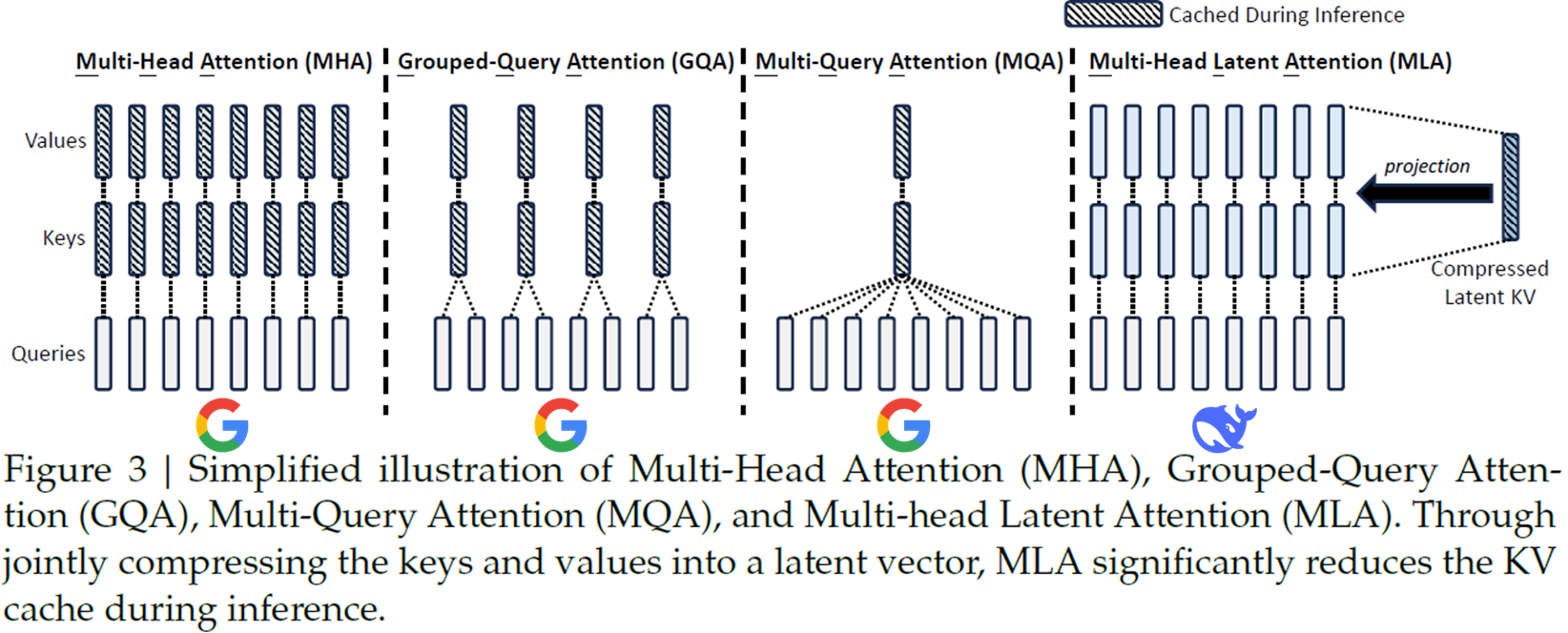

진화 순서 : MHA->MQA->GQA->MLA
기존 MHA가 transformer에서 제시된 아이디어이다. 다만 MHA는 모든 시점의 hidden state와 계산값들을 KV Cache로 저장하는데 많은 메모리를 필요로 한다. 이를 해결하기 위해 MQA를 제시하지만 이는 너무 성능 저하로 이어진다. 그래서 MHA와 MQA를 절충하는 GQA라는 아이디어를 내놓는다.
MLA의 경우 새로운 아이디어를 제시한다. Compressed Latent KV를 1개만 두고(MQA 방식 이용해서 만듦) 필요할 때 projection 시켜 사용하는 방식이다. 이를 통해 KV Cache도 줄이고 성능도 좋아졌다고 한다.

V2에서 제시한 전체 모델은 다음과 같다.

아래의 Attention 부분에 MLA가 적용되어 Latent c를 사용하는 것을 볼 수 있다.
관련 코드는 Hugging Face에 존재한다.
결과적으로 이러한 MoE 방식을 쓰면 활성화된 파라미터수를 줄일 수 있다.

* # of Total Params: V2 total 236B, V3 total 671B, R1 total 671B
V3내용을 조금 땡겨와서 추가 언급하자면 V2와 V3에서 DeepSeekMoE 부분에 적용되는 수식에 약간 차이가 있다.

DeepSeek-V2를 한 줄로 정리하자면 다른 오픈소스 LLM에 비비는 준수한 성능인데 중국어에 강한 LLM 이라고 할 수 있다.(참고로 V2에서도 GRPO 아이디어는 존재한다.)
추후 알아볼 내용: https://turingpost.co.kr/p/topic-31-reasoning-memory-reduction